







げんとくです。
今回はAsTobe初のTech記事ということで、音声ファイルの自動文字起こしプログラムを紹介します。
AsTobeではラジオ企画を行なっており、その宣伝の一環として、ラジオ内容を紹介する記事をこのサイト内に作成しています。
音声認識を活用した入力支援ソフトはすでに数多くありますが、こういった「長時間の会話内容を後から文字起こしする」というケースで使えるサービスは意外と多くありません。
あってもサブスク(定額)課金のため、十分な費用対効果が期待できるユースケースが限られる、という問題がありました。
今回紹介するAmiVoiceを活用した方法であれば比較的安価かつ、従量課金でサービスを利用できるので、多少ニッチなユースケースでも最低限の出費に抑えられて便利です。
この記事は誰のため?
- Pythonのhttpリクエストの仕様にあまり詳しくない、自分のような方の助けになればと思い書きました
- あまりしっかり分かっているわけではないので、その辺はご容赦を・・・!
- 「プログラム詳しくないけどサクッと音声文字起こししたい」という方の助けにもなると思います
今回のプログラムで作れるもの
この記事では以下画像のような出力結果を得られるプログラムを作成します。

AmiVoiceとは
簡単に説明すると、音声をAI解析して自動で文字起こししてくれるサービスです。
国内発のサービスのため、日本語の認識精度が高いことが特徴です。

AmiVoiceのソフトウェア製品は法人向けですが、APIは法人、個人関係なく使用することができ、発話時間に対して0.025円/秒〜の従量課金制でお財布に優しいです。
おまけに毎月60分は無料で使えるので、開発テストの段階でお金が取られる心配もありません。非常におすすめです。
料金について、詳細はこちらをどうぞ。
AmiVoiceのAPIはいくつか種類があるのですが、今回は大容量の音声データの音声認識に適した「非同期HTTP音声認識API」を扱います。
AmiVoiceはサンプルプログラムや日本語ドキュメントも充実しています。
しかし自分はそれだけで滞りなく実装できるスキルレベルではなく、特にPythonのrequestモジュールからどのようにリクエストすればよいか、という点で大変ハマりました。
なのでそこに重点を置いて、以下で解説していきます。
①POST
import json
import requests
from time import sleep
import pprint
import datetime
appkey = "<ここにAPPKEYを入力>"
#マルチパート送信の準備
file_ref = {"u":appkey, "d":"grammarFileNames=-a-general speakerDiarization=True","a":open("<ここに音声ファイルのパスを入力>","rb")}
#マルチパート方式でPOST
res = requests.post("https://acp-api-async.amivoice.com/v1/recognitions",files=file_ref)
print(res.text)※AmiVoiceのアカウント登録手順は割愛します。
登録後に得られるAPPKEYと音声認識したいファイルのパスの入力を忘れないようご注意ください。(テスト段階ではサンプルプログラム内の音声を使うのが手っ取り早いです)音声ファイルのパスの指定方式には、「絶対パス」と「相対パス」の2種類あります。
詳細は以下をご覧ください(別サイト)。
すでに述べた通り、Pythonによる通信にはrequestモジュールを使います。
POSTには最低3つのリクエストパラメータを渡してあげる必要があります。これらの送信方法はクエリ文字列送信とマルチパート送信の2通りがありますが、音声データはマルチパート送信が必須なので、最初から全てマルチパート方式で送信するのが良さそうです。 requestでのマルチパート送信はfileプロパティから行えるようです。
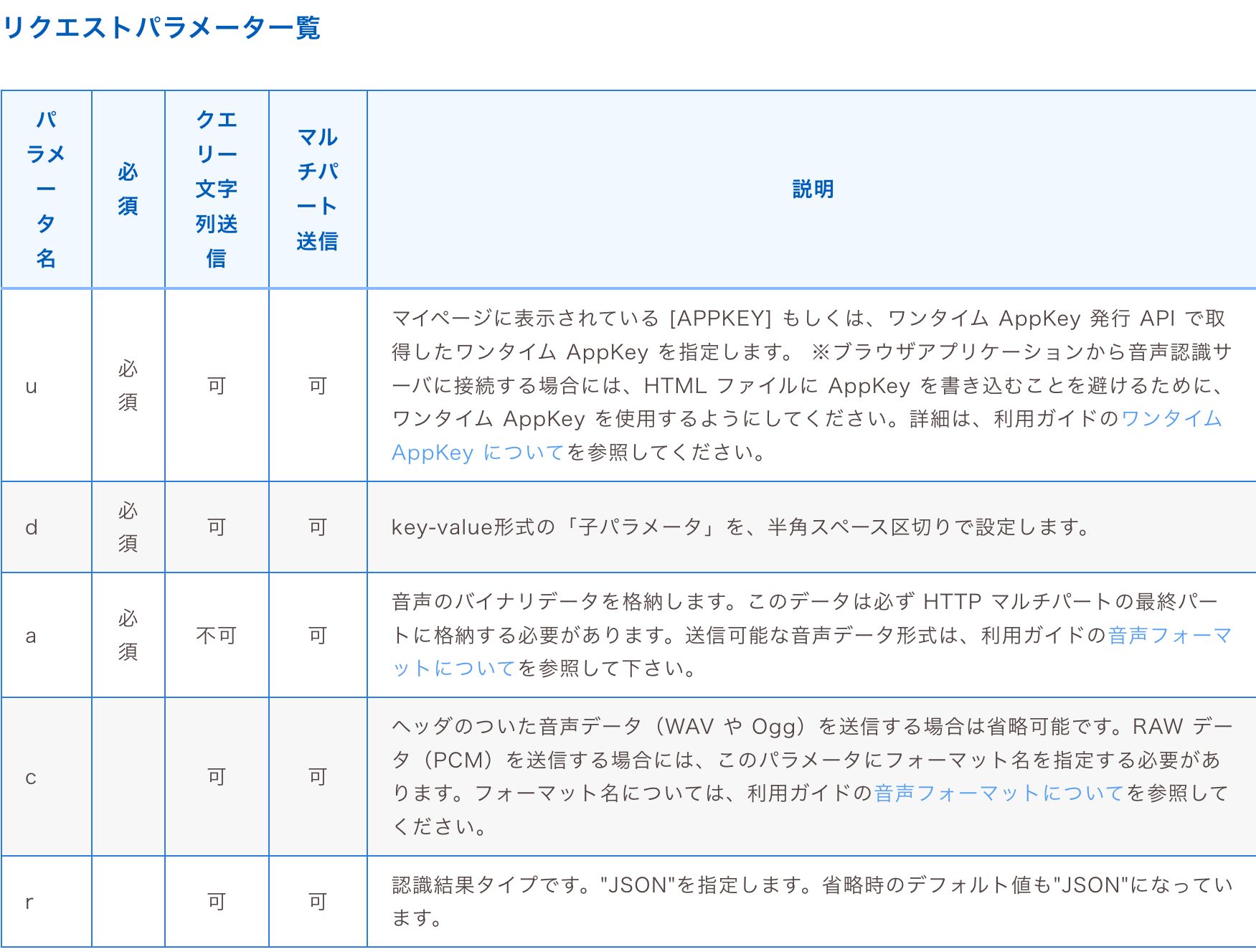
“d”パラメータの設定は”grammarFileNames”のみが必須であり、極論”-a-general”だけでも問題ありません。今回は話者ダイアライゼーション(声紋から話者を認識する)機能を使いたいので、ドキュメント通り<キー>=<パラメータ>を半角区切りでセットしています。

上手く行けば最後のprint文でsessionidと”…”が入ったtextが得られるはずです。
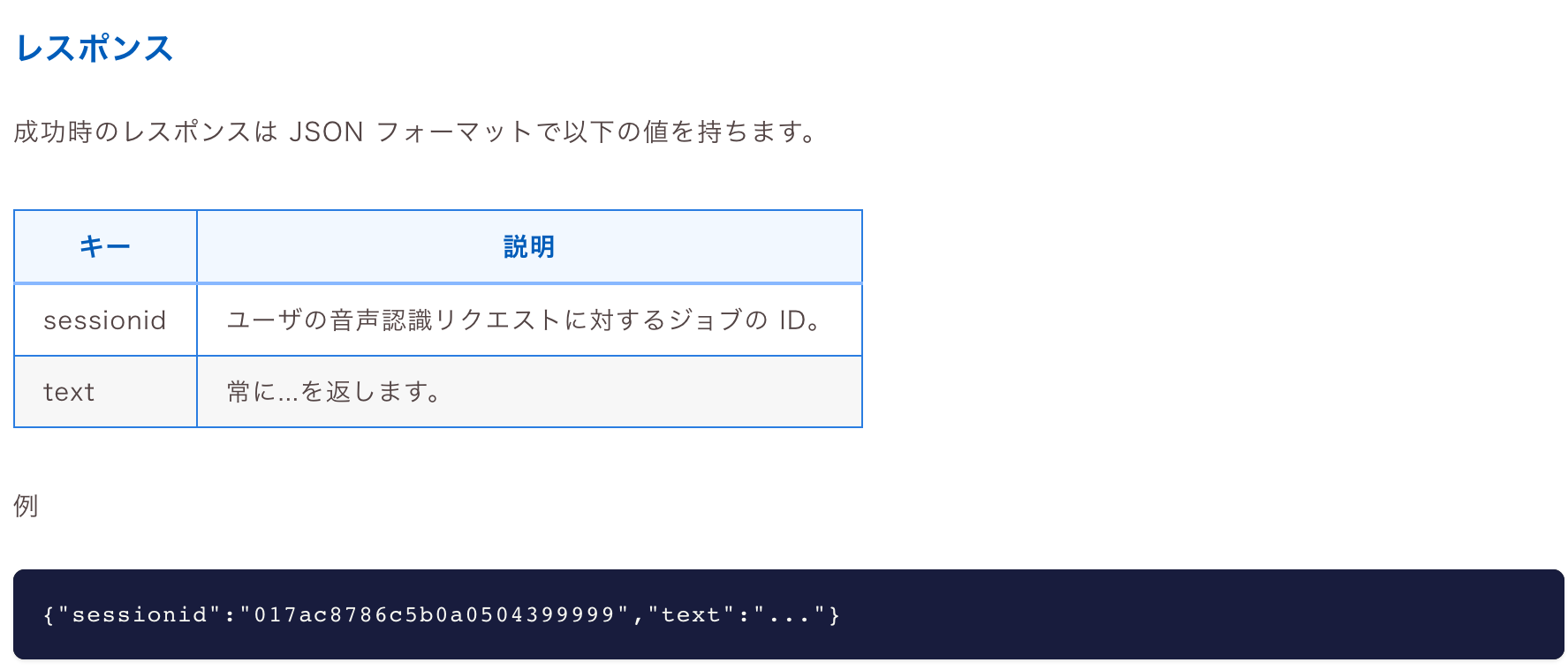
②GET
results = res.json()
sessionid = results["sessionid"]
print(sessionid)
#GETに必要なheader情報を準備
header = {"Authorization":f"Bearer {appkey}"}
#20秒ごとに音声認識の進捗情報をリクエスト
i = 0
while True:
sleep(20)
getres = requests.get(f"https://acp-api-async.amivoice.com/v1/recognitions/{sessionid}",headers=header)
results = getres.json()
if results["status"] == "completed":
print("認識完了")
break
print(results)
i += 1
if i == 30:
print("タイムアウト")
exitこのプログラムでは20秒ごとにGETリクエストを実行し、”status”が”completed”であればループから抜けるよう実装しました。
③テキストファイルへの書き込み
with open("<テキストファイルのパス>",mode="w") as f:
for sentence in results["segments"]:
pprint.pprint(sentence)
#話始めの時間の取得、○分×秒への変換
starttime = sentence["results"][0]["starttime"]
td = datetime.timedelta(milliseconds=starttime)
minute, second = divmod(td.seconds,60)
f.write(str(minute)+"分"+str(second)+"秒 ")
f.write(sentence["results"][0]["tokens"][0]["label"])
f.write("\n")
f.write(sentence["text"])
f.write("\n")
print("完了")※任意のフォルダにテキストファイルを作成し、パスを記述してください。
最後にテキストファイルに書き込みます。
自分の場合、ここからGoogleドキュメントなど好きな場所にコピペする形がやりやすいです。決まったアウトプット先がある場合は自由にアレンジしてください。
あらかじめ作っておいたテキストファイルを都度開いて上書きする仕様です。
話し始め、話終わりの時間がミリ秒の単位で取得できるので、単位変換して「○分×秒」の形で表示できるようにしています。
話者ダイアライゼーション機能は「speaker0」「speaker1」のような形で出力してくれて、本プログラムの出力結果にもそのまま反映されます。
プログラム側で例えば「hogehogeさん」のように設定することも可能ですが、出力後にコピペ先の媒体で置換処理をかける方が楽だろうと考えてそのままにしました。
終わりに
個人的な話で恐縮ですが、本件は一度AsTobeメンバーの後輩とプログラムを書き上げた後、パソコンデータが吹き飛んで独力で書き直した、という経緯があります。
最初に書いたときに記事を作っていれば、こんな苦労はしなかったのに・・・と思いつつ、この機会に以前より細かい仕様を把握できたので、その点を反映させつつ本記事の執筆に至った次第です。
インターネットにはいつも助けられてばかりなので、今回の記事でどなたかの力になれていれば幸いです。
最後に、(Pythonメインでもないのに)本プログラム開発時のアドバイスをくれたり記事レビューに協力してくれた後輩に、心からの感謝を!
AsTobeメンバーでもある後輩の個人ブログはこちら!



















